Salesforce BulkApi 2.0
Bulk API 2.0 is a RESTful API that allows users to perform large-scale data operations on Salesforce objects. It’s designed to improve the performance and reliability of bulk data processing.
Limits of Bulk API 2.0:
Bulk API 2.0 has some limits that you need to follow:
- Daily limit: You can process up to 100 million records per 24-hour period using Bulk API 2.0. This limit is based on the number of records processed, not the number of jobs or batches created.
- Job limit: You can have up to 100,000 jobs in any state (Open, Upload Complete,in progress, job complete, Aborted, or Failed) at any given time. You can delete completed or aborted jobs to free up space for new ones.
- Data limit: You can upload up to 150 MB of data per job. The data must be in CSV format, and each record must be on a separate line.
- Field limit: You can include up to 10,000 fields per object in your job data. This limit applies to both standard and custom fields.
- Batch limit: Salesforce creates a separate internal batch for every 10,000 records in your job data. Each batch can take up to 10 minutes to process. If a batch fails or times out, Salesforce will retry it up to 10 times. If a batch still cannot be processed after 10 retries, the entire job will fail, and the remaining data will not be processed.
- Concurrency limit: You can have up to 25 concurrent jobs running at any given time. This limit applies to both Bulk API 2.0 and Bulk API 1.0 jobs combined.
- Query limit: You can query up to 15 GB of data per job. The query results must be retrieved within 7 days of job completion.
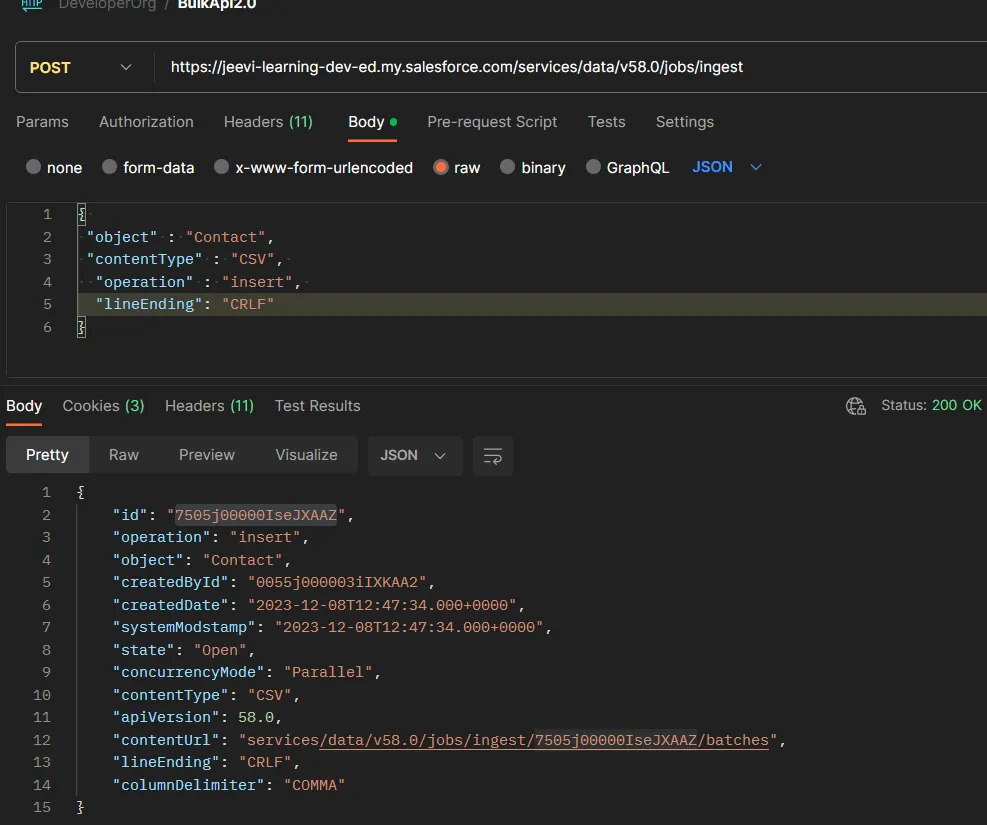
Step 1: First, we have to create job queue to run the bulk API callout.
Method – POST
Header – Authorization – Bearer AccessToken
Accept – application/json
Body – raw
{
"object" : "Contact",
"contentType" : "CSV",
"operation" : "insert",
"lineEnding": "CRLF"
}
Step 2: Once you execute the callout, you will get an ID for the job queue. We have to keep the job ID saved,as we are going to use that ID in the next callout.
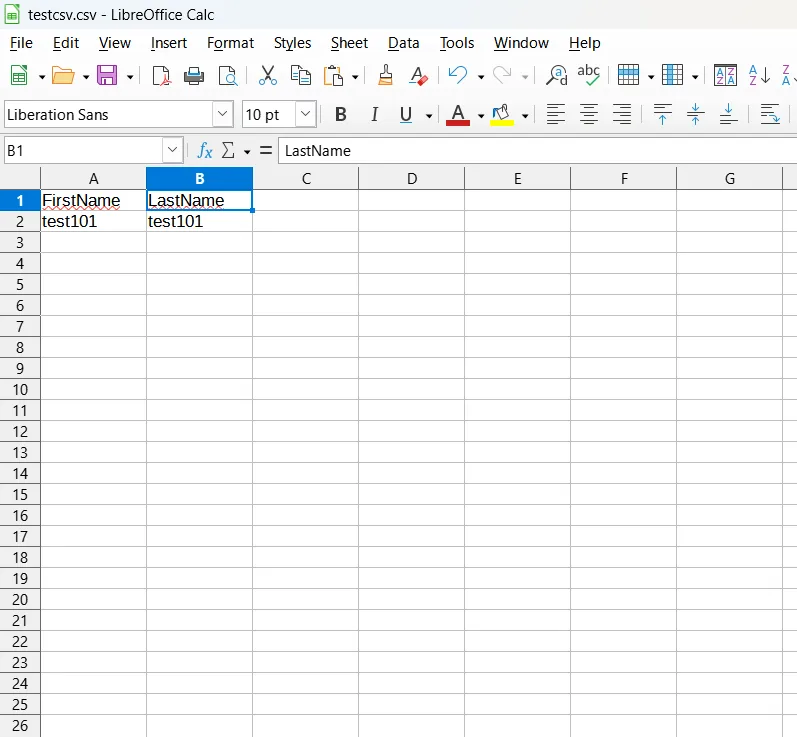
Step 3: Now we have to create the input data. Create a new CSV file with the data below
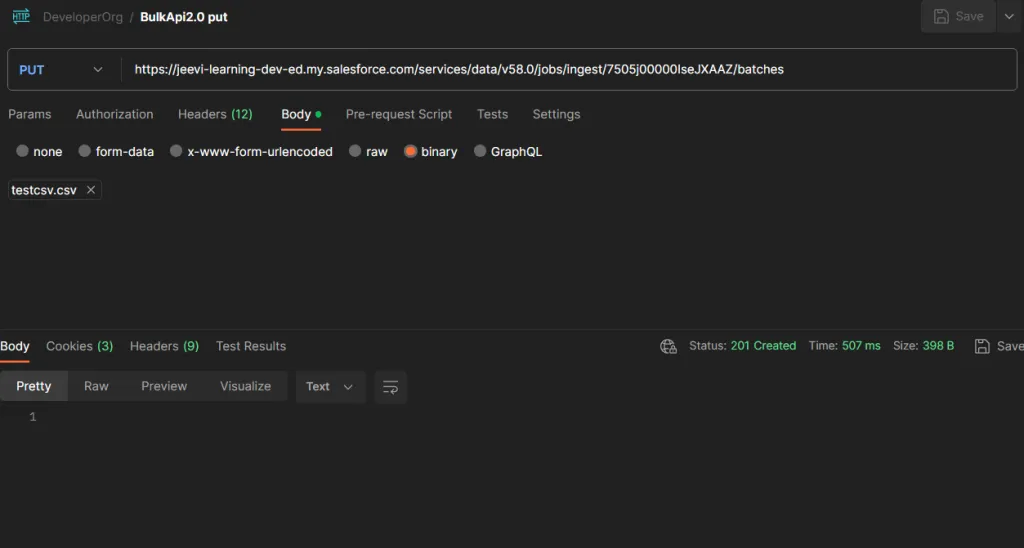
Step 4: In the previous callout, we created the job queue for bulk API. Now we are going to insert the records that need to be inserted.
Note: We have to use the job ID in this callout that we created in the previous callout.
Method – PUT
Header – Authorization – Bearer AccessToken
Accept – text/csv
Body – Binary (select the csv file)
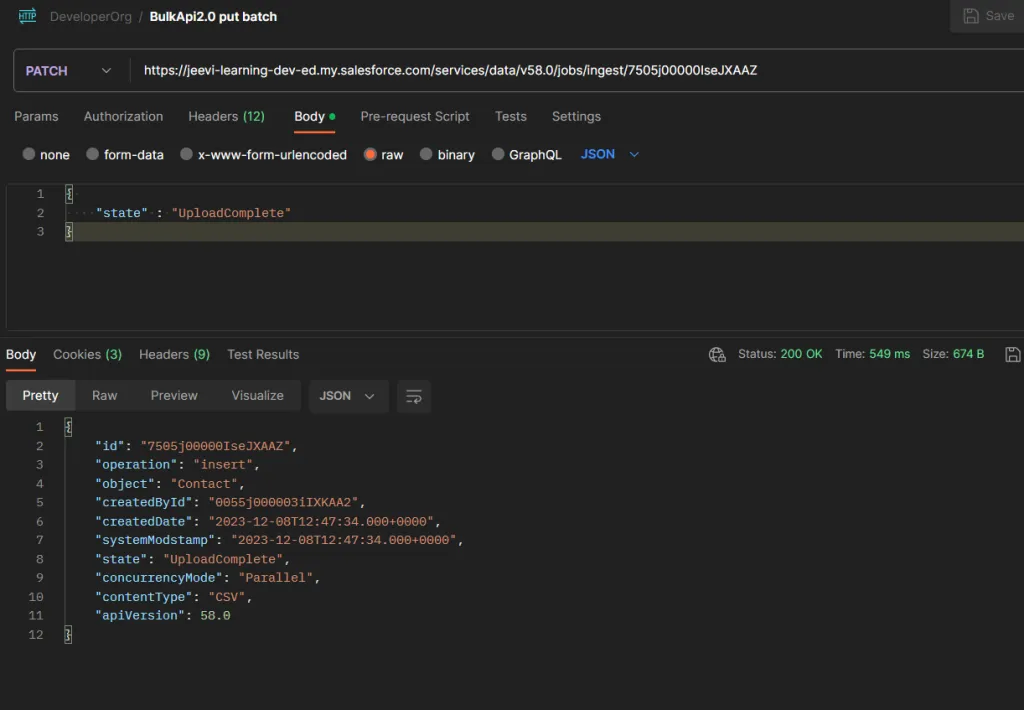
Step 5: Now the job will be executed. Once the job is executed, we have to update the job state. To do this, we have to make one more callout.
Method – PUT
Header – Authorization – Bearer AccessToken
Accept – application/json
Content-Type – application/json;charset=UTF-8
Body – {
{
“state” : “UploadComplete”
}
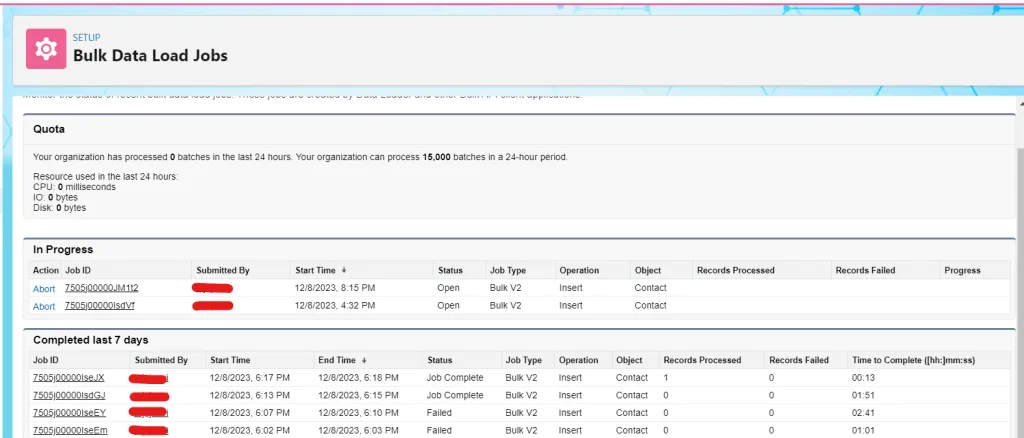
Step 6: Once the job is completed, records will be created. You can go and check the job details in the setup.
Setup → Bulk Data Load Jobs